Recorded Alert and Notification training webinar
I’ve worked with an operations support team for around 5 years in my previous company. Our team supported around 10 applications related to Human Resource, Finance and Workplace. Out of the 10 applications around 3-4 were tagged as critical and always-ON. Hence, we had to designate people to support these applications 24x7. The limitation of our team was that we were all co-located and worked on the same shift. So in order to support always-ON applications we had to designate support resources even if it’s night time, holiday or weekend. To manage cost, off-work hours resources we’re just designated as on-call. They were issued support phones to get alerts either from users or from the application itself.
Downtime and glitches are something a production support team would like to minimize if not totally avoid. But the reality is downtime and glitches occur in almost every application; be it due to infrastructure events, platform events or bugs in the application itself. What is crucial for the support team is their ability to detect these events as soon as possible and take action. In this post, we’ll cover a method of automatically detecting events and sending automated alerts using Retrace.
Retrace is better known for its application performance monitoring and debugging features. But if you look deeper, you’ll find a treasure trove of tools for production monitoring. Production monitoring is the process of keeping an eye on your application and infrastructure so that you’ll be able to respond to any event that causes a disruption in operation or availability. Automation is the most efficient and effective way of implementing production monitoring.
Detection
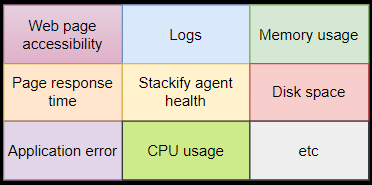
Retrace monitors and detects parameters and events in your applications and servers, but we’ll cover that in another post. Below are some examples of the commonly monitored parameters for production monitoring.
Alert and Notification
Retrace can generate default and custom alerts. Default alerts are common events in different applications such as CPU usage and memory usage. Custom alerts, on the other hand, are application specific alerts which are triggered by user defined thresholds.
Example Alerts

Among the available alerts, the production support team can choose which alerts should send a notification. Retrace also allows creation of notification groups, which can be used to designate the recipients of notifications depending on the alert level.
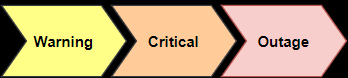
Certain monitoring parameters use thresholds to categorize an alert.
Alert Levels
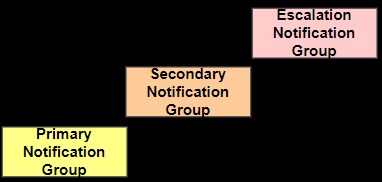
For critical and outage alerts, recipients of notifications can be different depending on the severity or lack of response by the first group. For example, if the primary group isn’t able to acknowledge or resolve the alert, the next notification will include the secondary notification group. If the secondary group still fails to acknowledge or resolve the alert, an escalation group will be included in the third notification.
In the case of my previous operations support team, the on-call resources were divided into 3 categories: one support resource is tagged as primary support, another one is tagged as secondary support and by default me or my manager was the point of escalation. The primary support was the first one to get all the alerts. In case for some reason, the primary support is unable to respond or receive the alert notifications then the secondary support steps in. If both the primary and secondary supports are not able to respond then me or my manager, as the escalation point, receives the alert and we usually contact other support resources who might be able to address whatever incident triggered the alert.
One thing which helped us a lot in our support work was the automated error detection and alert notification which we’ve leveraged in all our applications. We’ve put in place instrumentation in our applications that would allow alerts to be generated and notifications to get sent whenever there were critical issues or downtime especially for our always-ON applications.
Notification Levels
Notifications can be configured to be sent as an SMS, e-mail or Webhook message to popular collaboration and ticketing tools, such as Slack, MS Teams and JIRA.

Upon receipt of an alert notification, the recipient has an option to Snooze or Acknowledge the alert notification.

Until a notification is snoozed or acknowledged, it will continue to get sent unless the incident is already resolved.
The automated monitoring covered infrastructure, platform and application level events. These enabled our team to operate efficiently because we didn’t have to waste time doing manual checking and during off-work hours we just had to wait for our support phones to get messages or calls. The good news for Retrace subscribers is that the same level of monitoring and alerting features are available in Retrace.
Setup your production monitoring alerts now.
If you have questions or would like to talk about other Retrace features, you may book a meeting with your Customer Success Manager (nbontuyan@stackify.com).