Tracked Functions essentially allow you to track a sub-transaction or block of code within a larger transaction. For example, they can be implemented for tracking various Elasticsearch queries to uniquely identify them.
Retrace automatically tracks the usage of most common application dependencies and frameworks.
But what if you want to track something else? This is where Tracked Functions is really powerful.
Top 3 Reasons to Use Tracked Functions
There are probably endless ways you could use Tracked Functions. I can think of three different categories that they should all fall under.
1. Track time spent on sub-transactions as part of a larger transaction
Retrace automatically tracks how long web requests take (and non-web with a little work). But what if you want to break that down further? Let’s pretend you have a web application that receives uploaded files and processes them.
- Reads incoming file that is uploaded, cleans it up, validates it, and appends some additional data
- Writes the file to blob storage somewhere
- Writes a message to a queue to tell something else to process this
If you wanted more granularity around how long step 1 takes, tracked functions could help. All you would need to do is tell Retrace to track that block of code. Retrace would then report every time it happens and how long it takes. This would give you better visibility in to know how long that specific step of the entire process takes.
2. Track time spent on unsupported application dependency
Retrace automatically tracks dozens of common application dependencies. However, it will never support everything. Let’s pretend you are writing an application that uses OpenTSDB for storing time series data. You could use Tracked Functions to track the usage and performance of it.
3. Track different queries or operations of framework
Retrace provides great reporting around SQL queries. Unfortunately, that doesn’t work for things like Elasticsearch or MongoDB (at this time). At Stackify, we use Elasticsearch and wanted to report around how often we call specific queries and how long they take. We are able to accomplish this with Tracked Functions. Our code that executes searches against Elasticsearch is in a central location. With a couple lines of code, we were able to instrument our code and report our queries to Retrace.
How to Use Retrace Tracked Functions
The implementation is a little different depending on which programming language you are using.
Tracked Functions with .NET
To utilize Tracked Functions, you must add our StackifyLib nuget package to your project. You then surround your code as shown below with our tracer.
var tracer = StackifyLib.ProfileTracer.CreateAsTrackedFunction("Name the block of code");
tracer.Exec(() =>
{
//Do some stuff
});
Tracked Functions with Java
For Java, you can implement Tracked Functions by decorating the methods in your code or via a configuration file. See our docs for more details.
{
"Class": “com.company.SampleController",
"Method": “testMethod",
"TrackedFunction": true,
"TrackedFunctionName": "Tracked Function Test {{ClassName}}.{{MethodName}}"
}
Tracked Functions Reporting
Within the application dashboard for each of your applications, you can access Tracked Functions. It will show a list of all the Tracked Functions currently being tracked for your application.

If you select a specific web request or transaction, you can then see how that tracked function impacts the performance of that request.
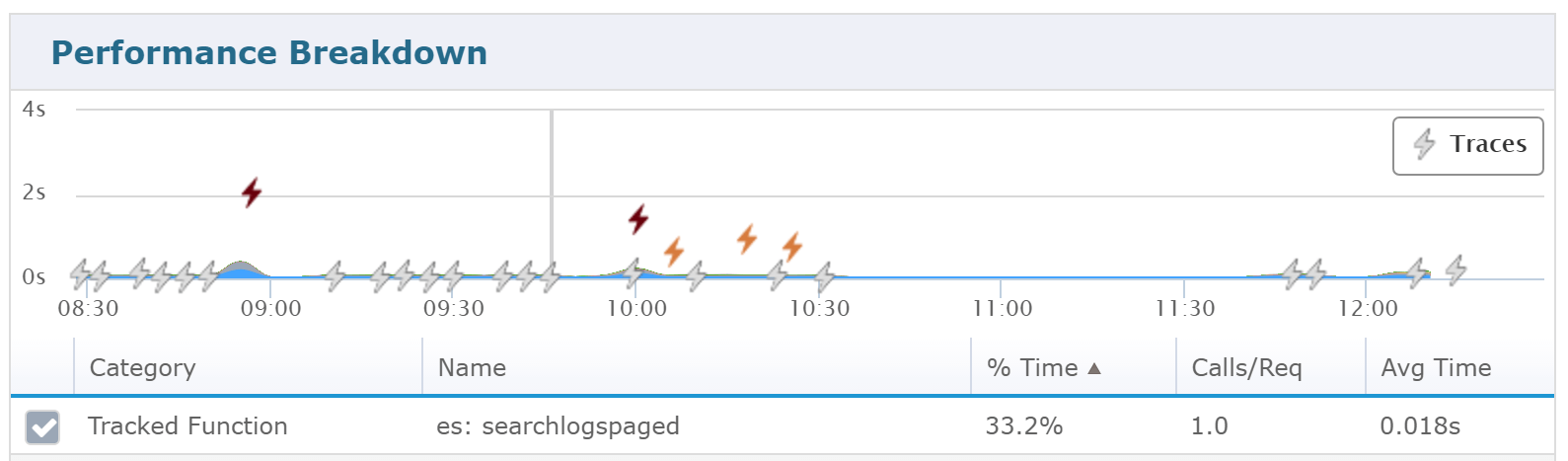
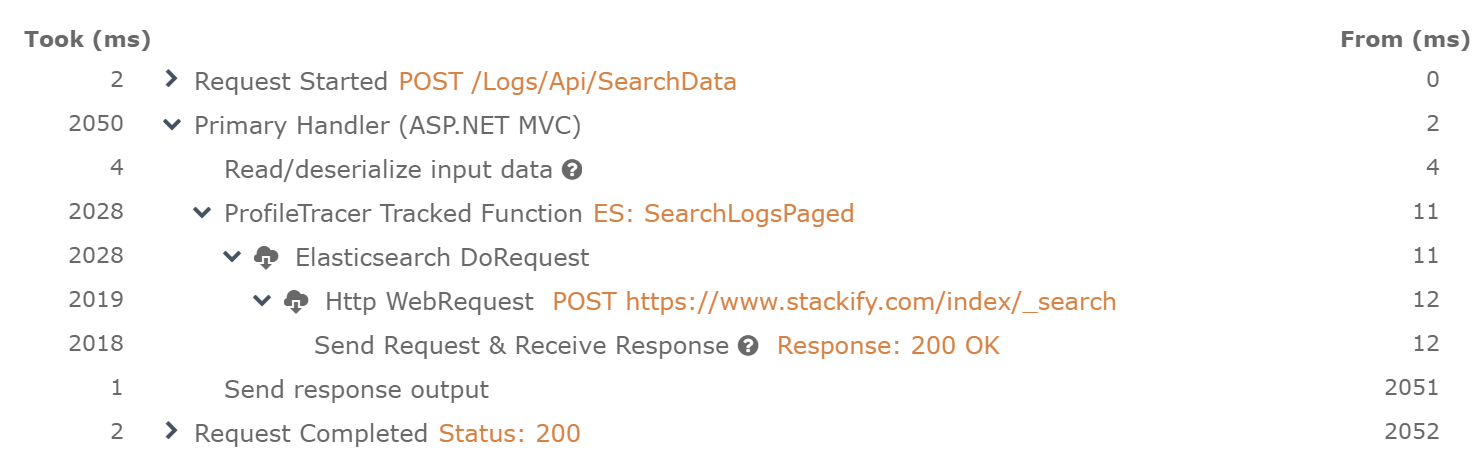
You can also see the tracked functions within the traces that are collected. In this example it is listed as ES: SearchLogsPaged.
Summary
Retrace provides a wide array of application monitoring capabilities. Tracked Functions allows you to get very granular in tracking the performance of your code. Hopefully, this article gives you a good review of why you would use them and some of the benefits.